DeepLearning 4j内には手書き文字のサンプルデータである『THE MNIST DATABASE of handwritten digits』が格納されている。今回はこのMnistデータベースを利用する方法について確認する。
■ Mnistデータベースとは?
THE MNIST DATABASE of handwritten digitst(*1)とは、NIST(アメリカ国立標準技術研究所)が作成した手書き文字のデータベースである。文字の画像認識の学習によく利用され、28x28ピクセルの文字画像が6万個と、それぞれの文字画像が表す分類値(0~9のどの数字を表した文字画像かを表す値)がセットになっている。
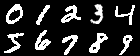 図:Mnistデータベース内の文字画像データの1部
図:Mnistデータベース内の文字画像データの1部
■ サンプルプログラム(Mnist画像の出力)
以下にDeepLearning 4jからMnistデータベースを取得し、データの内容を確認するため文字画像をファイル出力するサンプルプログラムを示す。
サンプルプログラム
import java.awt.image.BufferedImage;
import java.awt.image.WritableRaster;
import java.io.File;
import javax.imageio.ImageIO;
import org.deeplearning4j.datasets.iterator.impl.MnistDataSetIterator;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
public class MnistDataOutput1
{
public static void main( String[] args ) throws Exception
{
// Mnistデータをダウンロード
int batchSize = 64; // 1つ分のバッチで利用するサンプルデータ数。
int numExamples = 100; // 利用するサンプルデータの総数。
boolean binarize = true; // サンプルデータを正規化([0,1]の範囲に値を変換)するかどうか
boolean train = true; // 学習セット(train)か、テストセット(test)か
boolean shuffle = false; // サンプルデータをシャッフルするか
long rndSeed = 12345; // シャッフル時の乱数発生シード。適当な値でよい
DataSetIterator mnistTest = new MnistDataSetIterator( batchSize , numExamples , binarize , train , shuffle , rndSeed );
System.out.println( "dataset size : " + mnistTest.numExamples() );
// データ出力
// 注意点:サンプルデータはbatchSize個の塊(DataSet)単位で提供される。
// このため、numExamplesがbatchSizeの倍数でない場合はbatchSize*(i-1) < numExamples < batchSize*i
// となるbatchSize*i個のサンプルが取得される。
// 例 :batchSize=64 , numExamples=100の場合は64*2=128個のサンプルが取得される
for( int i=0 ; mnistTest.hasNext() ; i++ )
{
// データセットを1つ取得
DataSet ds = mnistTest.next();
// データセット内のサンプルデータをそれぞれ出力
for( int j=0 ; j<ds.numExamples() ; j++ )
{
// サンプルデータを1つ取得
INDArray data = ds.get(j).getFeatureMatrix().mul(255);
System.out.println( String.format( "[Dataset %05d-%05d]" , i , j ) );
System.out.println( "shape : " + toStr( data.shape() ) );
System.out.println( "length : " + data.length() );
System.out.println( "rank : " + data.rank() );
System.out.println( "order : " + data.ordering() );
System.out.println( "stride : " + toStr( data.stride() ) );
System.out.println( "label : " + ds.get(j).getLabels() );
System.out.println( "label : " + ds.get(j).getLabelNames() );
// 画像として描画
int width = 28;
int height = 28;
BufferedImage img = new BufferedImage(width, height, BufferedImage.TYPE_BYTE_GRAY );
WritableRaster r = img.getRaster();
byte[] buf = new byte[data.length()];
INDArray dataLinear = data.linearView();
for( int k=0; k<buf.length ; k++ )
{
buf[k] = (byte) Math.round( dataLinear.getInt(k) );
}
r.setDataElements( 0, 0, width, height, buf );
// ラベルを数字として取得
String label = "";
for( int k=0 ; k<ds.get(j).getLabels().length(); k++ )
{
if( ds.get(j).getLabels().getDouble(k) == 1.0 ){ label += k; break; }
}
// ファイル出力
String fileName = String.format( "%05d-%05d(%s).png" , i , j , label );
File f = new File( "output/" + fileName );
ImageIO.write( img , "png" , f );
}
}
}
protected static String toStr( int[] array )
{
String str = "";
for( int i : array ){ str += "," + i; }
str = str.substring( 1 , str.length() );
return str;
}
}
実行結果
ファイル出力結果

dataset size : 100
…中略…
[Dataset 00000-00000]
shape : 1,784
length : 784
rank : 2
order : c
stride : 1,1
label : [0.00, 0.00, 0.00, 0.00, 0.00, 1.00, 0.00, 0.00, 0.00, 0.00]
label : []
[Dataset 00000-00001]
shape : 1,784
length : 784
rank : 2
order : c
stride : 1,1
label : [1.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00]
label : []
…略
解説
Mnistデータベースのデータを取得するにはMnistDataSetIteratorクラスを利用する(17行目~23行目)。MnistDataSetIteratorクラスでは、以下のような構造のデータを保持している。
図:Mnistデータベースのデータ構造イメージ
データの一番小さな集まりはExampleと呼ばれるDataSetクラスである。Exampleは教師データ1つ分に相当し入力値をfeatureMatrix変数、出力値をlabels変数として保持している。
ExampleはMnistDataSetIteratorコンストラクタの第一引数で指定した個数毎にグルーピングされ、DataSetクラスに格納される。このDataSetのことをミニバッチと呼ぶ。教師データすべてで一括学習する方法をバッチ学習と呼ぶのに対して、教師データを小さなグループ(ミニバッチ)に分け学習を複数回実施する方法をミニバッチ学習と呼び、ミニバッチはこのミニバッチ学習で利用する教師データのグループに相当する。
ソースコードに照らしてみてみると、34行目ではミニバッチを取得し、40行目~48行目でミニバッチ内のj番目のサンプル情報を取得している。教師データ(Example)の内容について、標準出力を確認してみると以下の情報を保持していることが分かる。
| 変数 |
値 |
内容 |
| rank |
2 |
入力データの次元数 |
| shape |
1,724 |
入力データの各次元の要素数 |
| length |
724 |
入力データの総要素数 |
| ordering |
c |
INDArray::linearView関数を呼び出して全要素を次元数1の配列に変換する際の
要素格納順序。値の意味は以下の図のとおり。
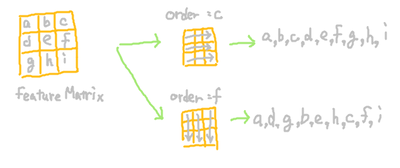 |
上記から28x28ピクセルの2次元の画像情報は1x724(=28x28)の1次元配列に変換されて格納されていることや、RGB値ではなくグレースケール値で格納されていることが分かる。自ら入力データを作成する場合などは、このデータ形式(1x724の1次元配列を持つINDArray)でデータを作成しなければいけない点が注目する点である。
画像出力についてはBufferedImageクラスに対してピクセルデータを設定し(51行目~61行目)、ImageIOとして出力(73行目)しているだけである。画像出力の注意点としては、DeepLearning 4jはJDK1.7準拠であるためサンプルでは画像ファイル出力にJavaFXではなくAWTを利用している点があげられる。
■ 参照
- Yann LeCun「THE MNIST DATABASE of handwritten digits」
- ND4J 「ND4J User Guide」